前言
现代的业务系统设计中,无论是面经还是实际应用,一旦探讨到高并发,高QPS,高性能,似乎都会不可避免地滑向 冗余 的深渊。
缓存、分布式、分库分表、预计算…… 这些常见的设计方案,本质上都是在牺牲空间换时间,通过冗余数据来提高系统的性能。
倘若只是冗余数据库的几个属性,借用CDN外部服务缓存倒是还算可以接受,但是一旦涉及到分布式多节点、多数据源、甚至微服务,系统整体的复杂度就会因为一系列状态同步、数据一致性问题而急剧增加。
那么,有没有一种设计方案,是不基于冗余数据,却能在高并发场景下保持高性能呢?
先来康康 Disruptor
Disruptor, 全名为 LMAX Disruptor,是一个开源的Java并发框架,用于在高并发情况下提供高性能的内存读写操作。
虽说是用Java实践的,但其精妙的核心设计却可以抽象出来。
它本质上是一个无锁的队列,通过避免锁竞争,减少线程上下文切换,提高了并发性能。
在这里,我不想局限于 Disruptor 框架本身的使用,仅仅讨论 Disruptor 核心的设计思想。
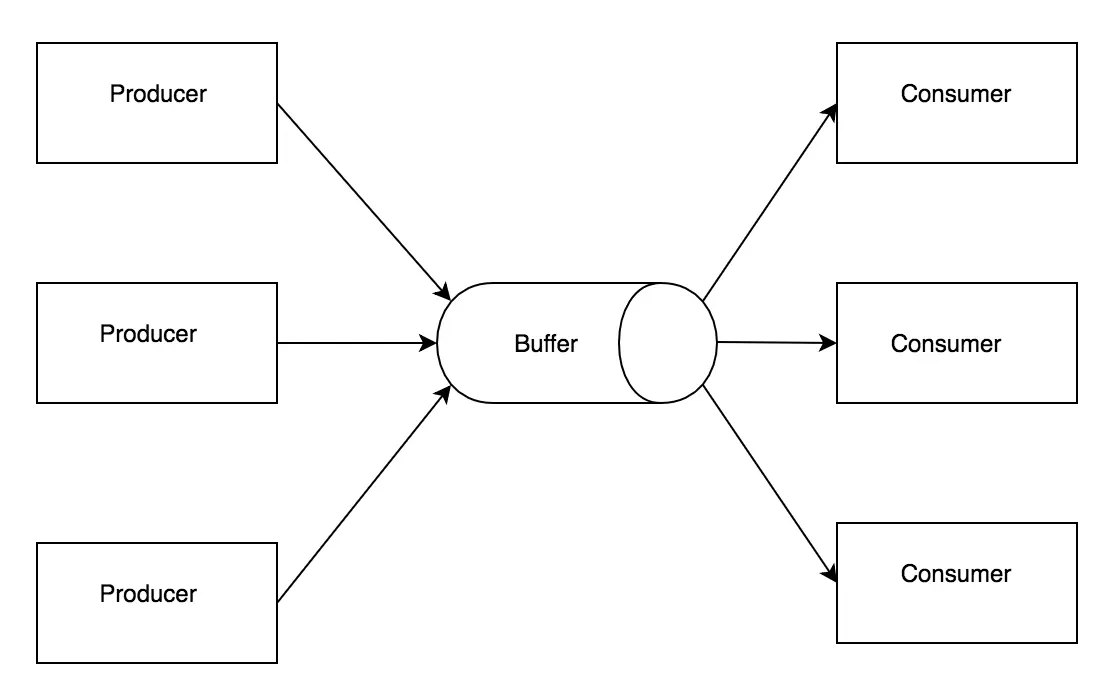
1. Producer-Consumer Model
即 生产者-消费者模型 , 它最大的作用是能够将生产者和消费者解耦,以及在调用链中引入一些花活儿。
在这里,我们可以在生产者和消费者之间引入一个队列,生产者将数据放入队列,消费者从队列中取出数据进行处理。
这样,我们就能在一定程度上抹平生产者和消费者之间的速度差异。
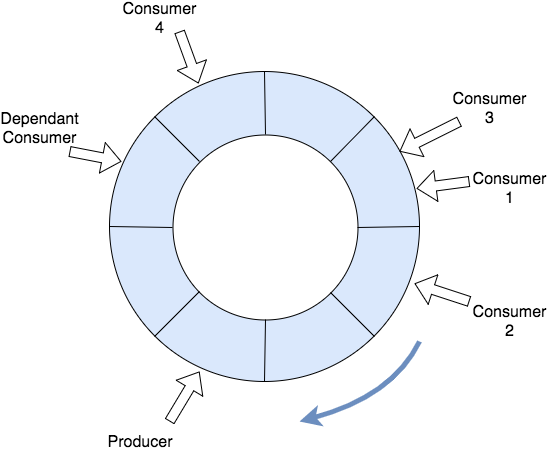
2. Ring Buffer
即 环形缓冲区,是 Disruptor 的核心数据结构,也是它有别于传统队列的特别之处。
虽说它本质上就是一个环形队列,再基础一点,甚至仅仅就是个数组,但是它的设计从某种意义上非常精妙。
2.1 Size
Ring Buffer 的大小是固定的,这意味着它的内存空间是有限的。
通常来说,Ring Buffer 的大小是2的幂次方,这样可以通过位运算来实现取模操作,提高性能。
2.2 Sequencer
Sequencer 是 Ring Buffer 的核心,它负责维护 Ring Buffer 的状态,以及控制 Producer 和 Consumer 的行为。
在一个 Ring Buffer 中,每个 Slot 都有且仅有一个唯一的 Sequence,用于标识其在 RingBuffer 中的固定位置。
同时,Sequencer 会维护所有 Producer 和所有 Consumer 的 Cursor:
- Producer Cursor:表示 Producer 已经放入的最大 Sequence;
- Consumer Cursor:表示 Consumer 已经消费的最小 Sequence;
当某个 Producer 将一个或多个数据放入 Ring Buffer 时:
- 先获取 Producer Sequence
n; - 计算得到新的 Sequence
m; - 更新 Producer Cursor 为
m; - 如果此时 Producer Cursor 仍然为第一步中
n的值,说明🈚️并发问题,🉑写入; - 将数据放入 Ring Buffer 申请到的一个或多个 Slot 中;
值得一提的是,第四和第五步是标准的 CAS 操作,即 Compare And Swap,是一种无锁的原子操作。
它能在相当程度上避免锁竞争,提高并发性能。
当某个 Consumer 从 Ring Buffer 中取出一个或多个数据时:
- 不同于 Producer, Consumer 是允许多个同时指向同一个 Sequence 的。
- 具体由哪个 Consumer Consume,取决于 Sequencer 。
- 根据业务系统的需要,可以指定 单消费者 、多播 或 广播 等。
2.3 Wait Strategy
其实叭,我们也并不能说 Ring Buffer 就是完全无锁的,因为如果 Ring Buffer 中没有数据,Consumer 就需要等待。
而 Wait Strategy ,即等待策略,这一部分中 可能 会涉及到锁。
但这里的锁在整个系统对实际的并发性能影响并没有其它因素来得大,它更多与 CPU 的资源使用效率有关。
再来康康 Event
其实这里的 Event 和 Disruptor 并没有直接的关系。
但是既然讲到 LMAX 了,那就不得不提他们结合 Event Sourcing 和 Disruptor 的例子了。
1. Event Sourcing
Event Sourcing,即 事件溯源 是一种架构层级的设计模式,它的核心思想是将系统的状态变更抽象为一系列事件,而不是直接修改状态。
相比于传统的 CRUD 直接操作数据库,Event Sourcing 的主要优势在于:
- 可以追溯系统的历史状态;
- 可以实现事件回放,用于系统的恢复和重放;
当然,我个人想强调的并不是上面这些老调重弹的玩意儿。
事实上,LMAX 的做法比大多数人想象的更加激进。
2. Full Cache
在 LMAX 的架构中,所有 的相关数据在应用启动初期被载入到内存中。
对于查询,直接在内存中进行计算,而不是去数据库中走一遍IO。
这一惊为天人的设计并非空穴来风,而是有赖于现代CPU性能的提升与发展。
在百万、甚至千万级别的数据量下,内存计算的速度甚至远远超过了IO操作。
甚至,为了防止并发冲突,他们一方面在消息传递中引入了 Disruptor,另一方面在主业务中严格使用 单线程。
每秒轻松百万并发,大道至简。
那么,代价是什么呢?
最显著的代价,无疑是 你需要远远超出维护一个数据库所需的内存。
但是,如果你的业务量真的到了需要使用这个模式的级别,硬件成本对于你来说也不会是什么大问题。恭喜你🎉,你 完完全全 摆脱了传统的数据库事务模型。
这意味着原先一切基于事务 回滚 将不再有效,你需要重新设计你的系统来保证数据的一致性。恭喜你🎉,你的运维告诉你机房停机了,你从服务以来跑的所有数据全部丢失了。
事实上,这并不意味着 Event Sourcing 就和持久化水土不服,而是我们需要更优秀的东西来适配它。
3. Solution
在 LMAX 的架构中,Disruptor 被用于处理 Event 的生产和消费。
从某种意义上来说, Event 有的时候会比数据本身更加重要。
他们其实同样使用数据库,但是并不把数据库作为业务系统的“一等公民”。
和我们的业务系统一样,他们也需要一个持久而稳定的数据源,让他们的应用得以在启动的时候加载数据。
…………
好叭,不卖关子了,一句话解释,其实就是
将 Event 作为业务系统的核心,在业务流程中持久化 Event, 而非数据。
这一做法其实相当高明,回想一下你读写数据库里的数据的时候为了防止并发冲突做的那些蠢事儿,现在你可以 完完全全 摆脱它们了。
有的人可能会问🤔,咋,持久化 Event 就不会出现并发冲突了吗?
当然不会,因为你的事件是有序的,而有序且高效的基石正是我们先前提到的 Disruptor 。
同理,因为用户本身其实并不关心 Event,所以你的所有过程都可以异步执行,完全不会丧失响应性。
为了防止错误,你也可以定期地在后台悄咪咪地根据那些个 Event 重建数据,建立快照之类的。